
신문기사 테이블(아래표)을 생성하고, 일반 인덱스(위표)를 생성했다고 가정해보자.
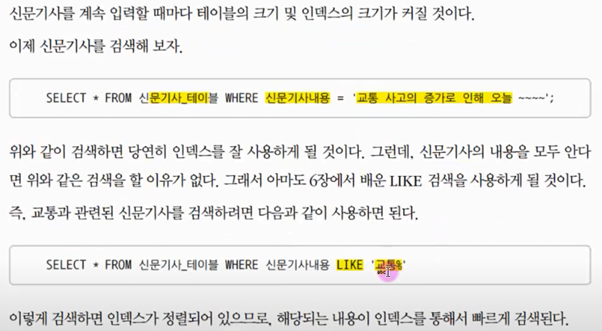
1. 신문기사의 내용을 모두 알아서 검색하면 당연히 빠르다.
2. 앞글자 like검색도 인덱스를 통하여 위위사진(신문기사 인덱스)처럼 정렬되어 있기에 검색이 빠르다.

하지만 위처럼 보통 앞뒤로 like 검색을 하는 경우가 일반적이다. 이럴 경우 일반 인덱스가 있어도 FullScan을 할 수 밖에 없다. 10년치의 기사에거 검색이라고 생각해보자. 결과적으로 매우 느리다.
전체 텍스트 검색은 이러한 문제를 해결해준다. 첫글자 뿐만 아니라, 중간의 단어나 문장으로도 인덱스를 생성해 주기 때문에 지금과 같은 상황에서도 인덱스를 사용할 수 있어 순식간에 검색 결과를 얻을 수 있다.


전체 텍스트 인덱스를 생성하는 방법 3가지








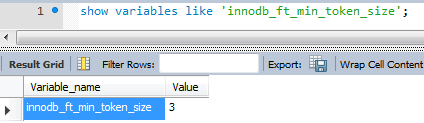
MySQL은 기본적으로 3글자 이상만 전체 텍스트 인덱스로 생성한다. 이러한 설정을 2글자까지 전체 텍스트 인덱스가 생성되도록 시스템 변수값을 설정해보자.

2글자 이상을 전체텍스트 검색으로 사용하려면 위처럼 ini파일에 추가해주고 서비스를 재시작해야함.

2로 변경되었는지 확인한다.

전체텍스트 검색을 위한 샘플데이터

지금은 데이터가 몇 건 되지 않아서 문제가 없지만, 대용량의 데이터라면 MySQL에 상당한 부하가 생길 것이다.

전체 텍스트 인덱스를 생성하고 인덱스 정보를 확인해 보자.
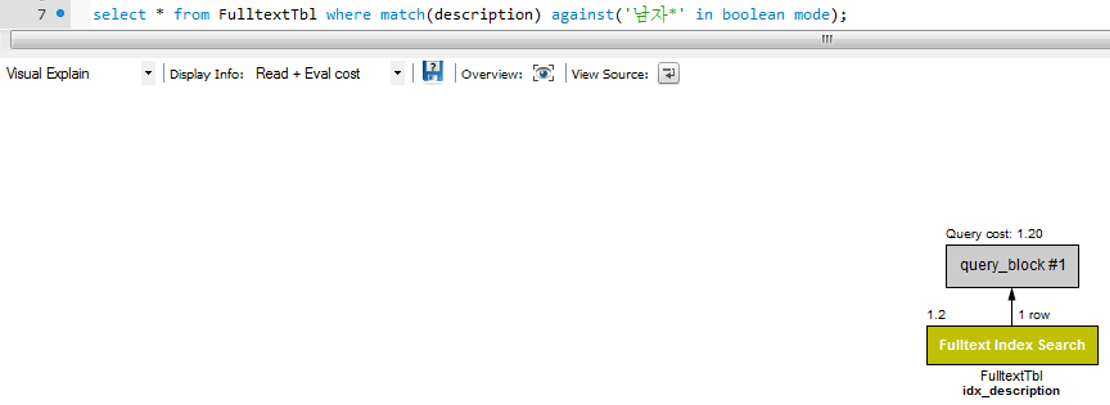
전체텍스트 인덱스를 검색함으로써 검색속도가 빠르게 검색될 것이다.

11. select 문장안에 match를 사용하면 매치되는 점수가 매겨진다.
5. 여자, 남자가 모두 나와서 높은 점수가 생성되었다.
3. 남자가 2번 나오긴 했지만, 동일한 단어이므로 1개만 나온 것으로 처리되어 점수가 낮음.
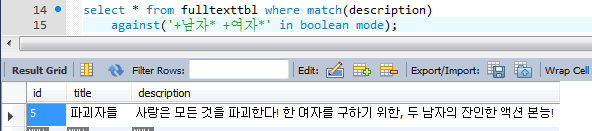
+연산자로 남자, 여자가 필수로 들어가는 문장을 검색한다.
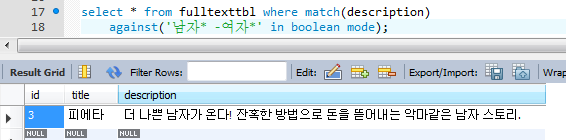
- 연산자로 남자가 들어있는 영화중에서 여자가 들어있는 영화를 제외시킴.
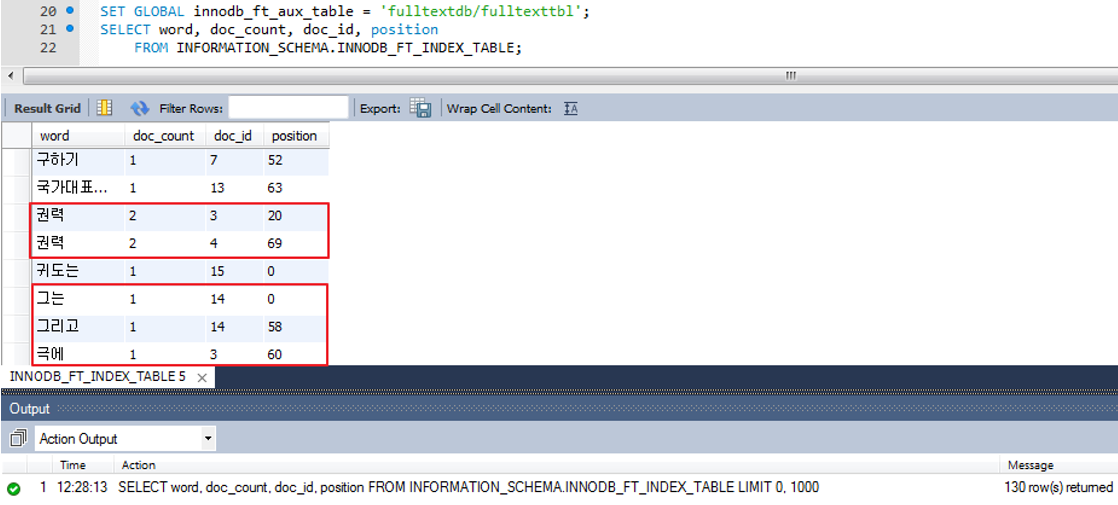
20~22. 위와 같은 쿼리로 전체텍스트 인덱스로 생성한 값들을 확인해볼수 있다.
1. 권력이라는 단어는 광해, 간첩에 나오므로 2로 표시된 것이다.
2. 그는, 그리고, 극에 등의 단어는 검색을 하지 않을 필요없는 단어들이다.
필요없는 단어를 삭제해보자.

24. 기존에 있던 인덱스에 중지단어를 추가하기 위해 인덱스 삭제
25. 사용자가 추가할 중지 단어를 저장할 테이블을 생성한다. 주의할 점은 테이블 이름은 아무거나 상관없으나 열 이름은 value와 varchar형태로 지정해야 한다.
26. 중지단어 등록 일단 3개만 등록함.
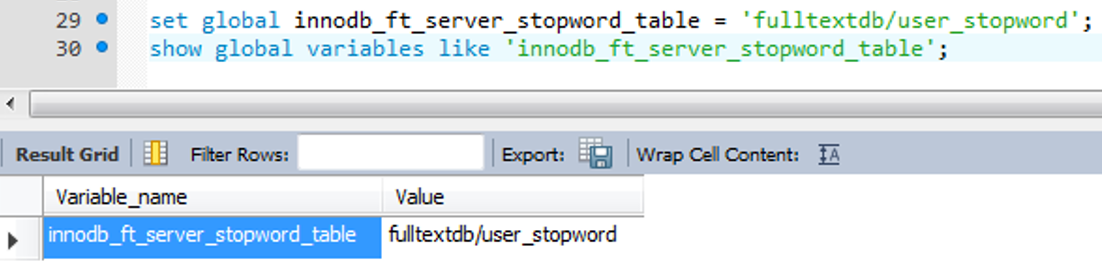
중지 단어용 테이블을 시스템 변수 innodb_ft_server_stopword_table에 설정해야한다. 주의할 점은 홀따옴표 안의 DB이름과 테이블 이름은 모두 소문자로 써야한다.

다시 전체 텍스트의 인덱스를 생성.
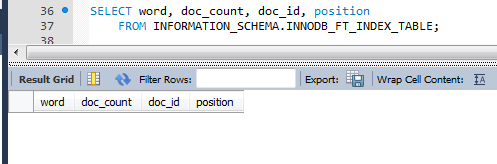
중지단어를 제외하고 보여야하는데 안보임 뭔가 잘못됐음. 이런식으로 하는거임.

파티션을 나눌때는 예로 10년간의 데이터가 저장된 테이블이라면, 아마도 과거의 데이터들은 주로 조회만 할 뿐 거의 변경이 되지 않을 것이다. 그러므로 작년 이전의 데이터와 올해의 데이터를 서로 다른 파티션에 저장한다면 효과적일 수 있다.
또 다른 예로는 각 월별로 업데이트가 잦은 대용량 데이터라면 각 월별로 파티션 테이블을 구성할 수도 있다.
* mysql은 1024개의 파티션을 지원하는데, 파티션을 나누면 물리적으로 파일이 분리된다. 그렇기 때문에 파티션 테이블은 파일이 동시에 여러 개 열린다. MySQL은 동시에 열 수 있는 파일의 개수가 시스템변수 open_file_limit에 지정되어 있다. 그러므로 파티션을 많이 나눌 경우에는 시스템 변수 open_file_limit의 값을 크게 변경시켜줄 필요가 있다.

* 회원을 파티션으로 구분하여 테이블을 생성할 때의 개념도.
> 테이블을 생성할 때 파티션 키를 함께 지정한다.
> 데이터를 입력할 때 지정된 파티션 키에 의해서 데이터가 각각의 파티션에 입력되는 개념.


5. 파티션 테이블에는 Primary Key를 지정하면 안된다. 기본키로 지정하면 그 열로 정렬이 되기 때문에 파티션으로 하면 안된다. 만약 기본키로 지정하려면 파티션에서 사용되는 열도 함께 지정해야한다. 이 예는 userID와 birthYear를 함께 기본키로 지정해야한다.
10. 파티션 테이블을 지정하는 문법은 테이블의 정의가 끝나는 부분에 partition by range(열이름)로 지정한다. 그러면 열 이름의 값에 의해 지정된 파티션으로 저장된다. 주의할 점은 열 이름은 숫자형의 데이터여야 하며 문자형은 오면 안된다는 것이다.
11. 첫번 째 파티션에는 1970년 이하 출생인 회원이 저장
12. 두번째 파티션에는 1978년까지 출생된 회원이 저장된다.
13. 세번째 파티션에는 1979년 이후의 출생한 회원이 저장된다. Maxvalue는 1978 초과(=1979이상)의 모든 값을 의미한다.
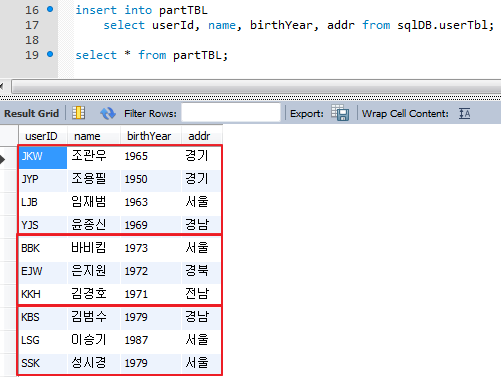
16. 파티션테이블에 데이터를 입력하면 파티션 키에 의해서 데이터가 각 파티션으로 나뉘어 진다.
19. 데이터가 출력된 결과를 보면 part1, part2, part3 파티션 순서로 조회된 것을 확인할 수 있다.

21. 파티션을 확인. 파티션 이름, 파티션 일련번호, 파티션에 저장된 행 개수 등을 알 수 있다.

1965년 이전에 출생한 회원을 조회해보자. 이는 파티션1만 조회해서 결과를 가져왔을 것이다. 실제 대용량 데이터였다면 파티션2와 파티션3은 아예 접근하지도 않았으므로 상당히 효율적인 조회를 한 것이다.

어느 파티션을 사용했는지 확인하려면 쿼리문 앞에 explain partitions문을 붙이면 된다. 예상대로 파티션1만 접근해서 결과를 냈다.
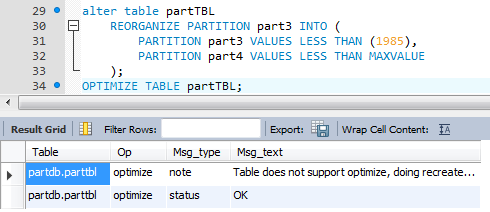
* 파티션 테이블 나누기(수정)
29~33. 만약 파티션3을 1979~1985(파티션3)와 1986 이후(파티션4)로 분리하고자 한다면 alter table … reorganize partition문을 사용.
34. 파티션을 재구성하기 위해 optimize table 문을 수행해줘야 한다.
* 파티션을 추가하기 위해서는 ALTER TABLE … ADD PARTITION문을 사용해야한다. 그런데 MAXVALUE로 설정되어 있는 파티션 테이블에는 파티션을 추가할 수 없다. 이런 경우에는 지금과 같이 파티션을 분리하는 방식으로 추가해야한다.

기존의 파티션3에 있던 데이터3개가 파티션3에 1개 파티션4에 1개로 자동으로 분리되었다.

* 파티션 합치기(수정)
36~39. 1970 이하인 파티션과 1971~1978인 파티션2를 합쳐서 1978 이하를 파티션12로 합침.
40. 파티션 재구성

합쳐진 파티션12에 기존파티션1의 데이터 4개와 파티션2의 데이터3개가 합쳐진 데이터 7개가 들어간 것이 확인된다.

42. 파티션테이블에서 일부파티션 삭제
43. 파티션테이블 재구성

파티션12에 있던 데이터 7건은 파티션과 함께 삭제되었다. 즉, 파티션을 삭제하면 그 파티션의 데이터도 함께 삭제되므로 주의해야 한다.
* 대량의 데이터를 삭제할 때 파티션을 삭제하면 상당히 빠르다. 파티션의 데이터를 모두 삭제할 때는 delete문보다는 파티션 삭제를 하는 것이 더 효율적이다.
* 파티션 제한사항
1. 파티션 테이블에 외래 키를 설정할 수 없다. 단독으로 사용되는 테이블에만 파티션을 설정할 수 있다.
2. 스토어드 프로시저, 스토어드 함수, 사용자 변수 등을 파티션 함수나 식에 사용할 수 없다.
3. 임시 테이블은 파티션 기능을 사용할 수 없다.
4. 파티션 키에는 일부 함수만 사용할 수 있다.
5. 파티션 개수는 최대 1024개까지 지원된다.
6. 레인지 파티션은 숫자형의 연속된 범위를 사용하고, 리스트 파티션은 숫자형 또는 문자형의 연속되지 않은 하나 하나씩의 파티션 키 값을 지정한다.
7. 리스트 파티션에는 maxvalue를 사용할 수 없다. 즉, 모든 경우의 파티션 키 값을 지정해야 한다.
'SQL' 카테고리의 다른 글
| [MySQL_MariaDB] 커서_loop_select 한줄한줄 읽으며 처리 (0) | 2021.03.16 |
|---|---|
| [MySql_mariaDB] 스토어드 함수 Function (0) | 2021.03.15 |
| [SQL] JOIN 조인 (0) | 2021.03.14 |
| [mariadb_mysql] 대량의데이터(TEXT,CLOB) (0) | 2021.03.13 |
| [mysql_mariadb] 내장함수_foreignkey수정 (0) | 2021.03.12 |



